Endpoint browser を使って、エンドポイントに入っている RDF データの RDF-config(のたたき台)を作成することができます
1) Endpoint browser でエンドポイントにアクセスする
Endpoint browser に移動して、目的のエンポイントと最初のノードの URI を入力して "start" をクリックします(ローカルのエンドポイントの場合は Docker 版が利用できます)
最初のノードは、そこから多くのノードにたどって行けるような RDF ネットワークの最上位クラスっぽいエンティティの例をいれます(図中の例ではプロテオームのある実験プロジェクトのエントリに対応するURI)
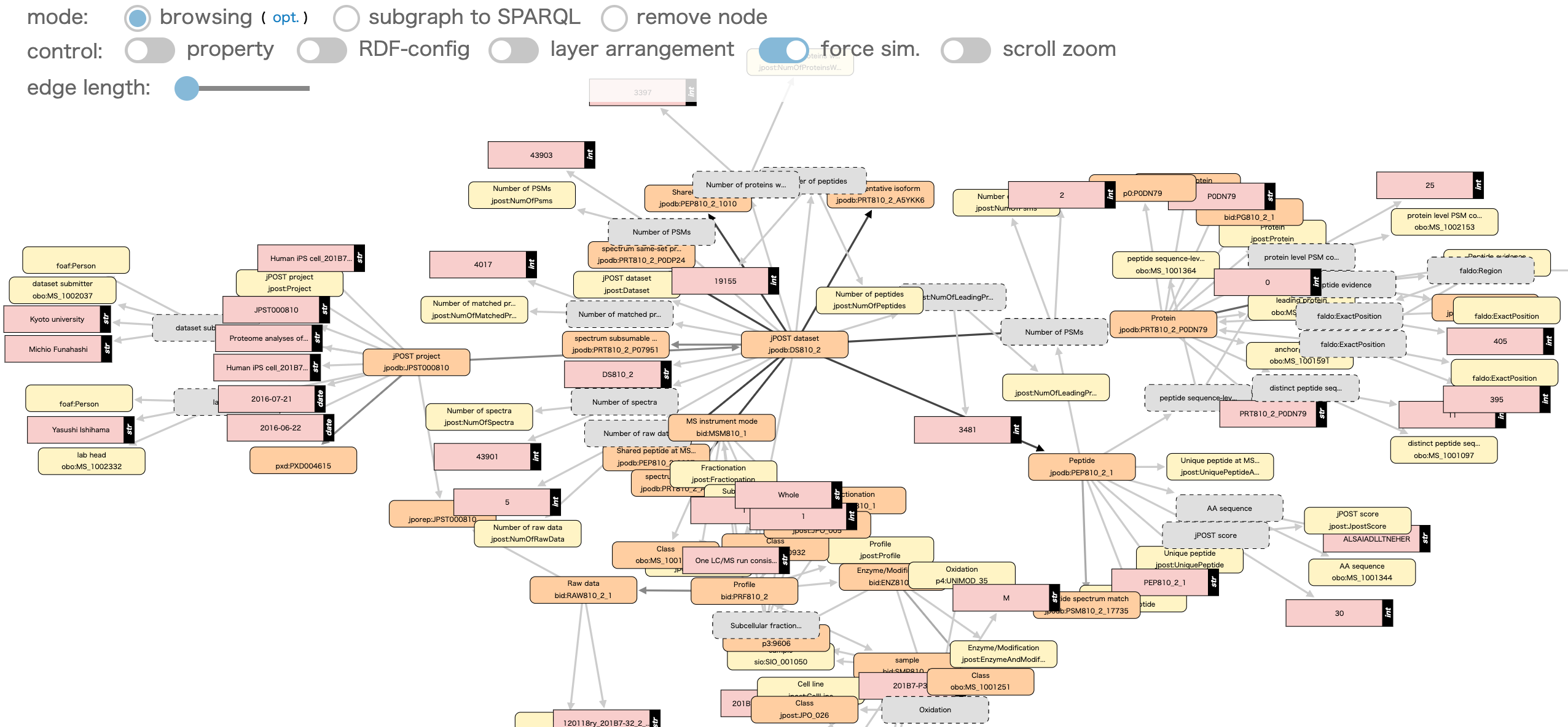
下のようなネットワーク図が表示されます
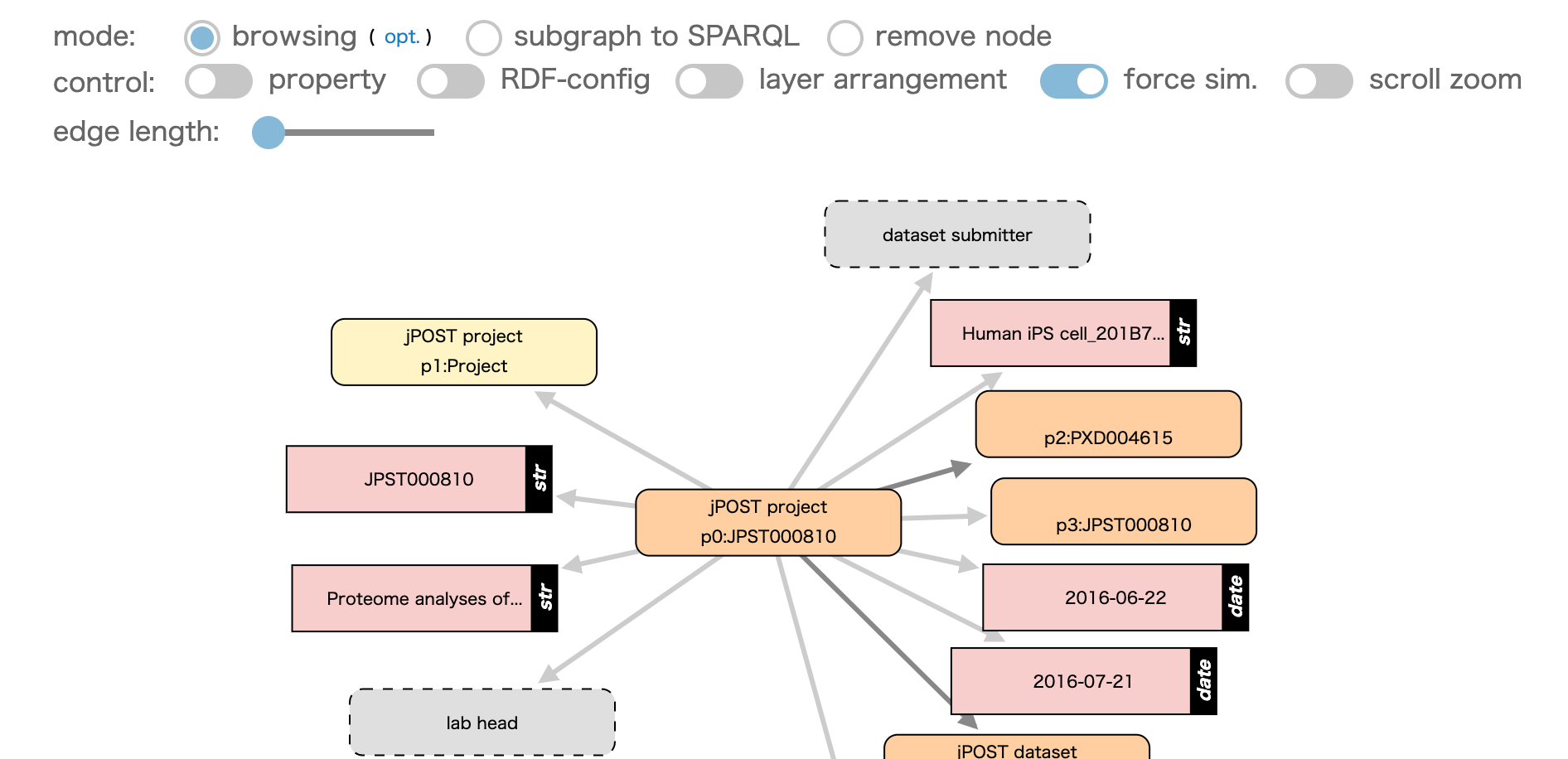
ノードをクリックすると、RDF データが展開していきます
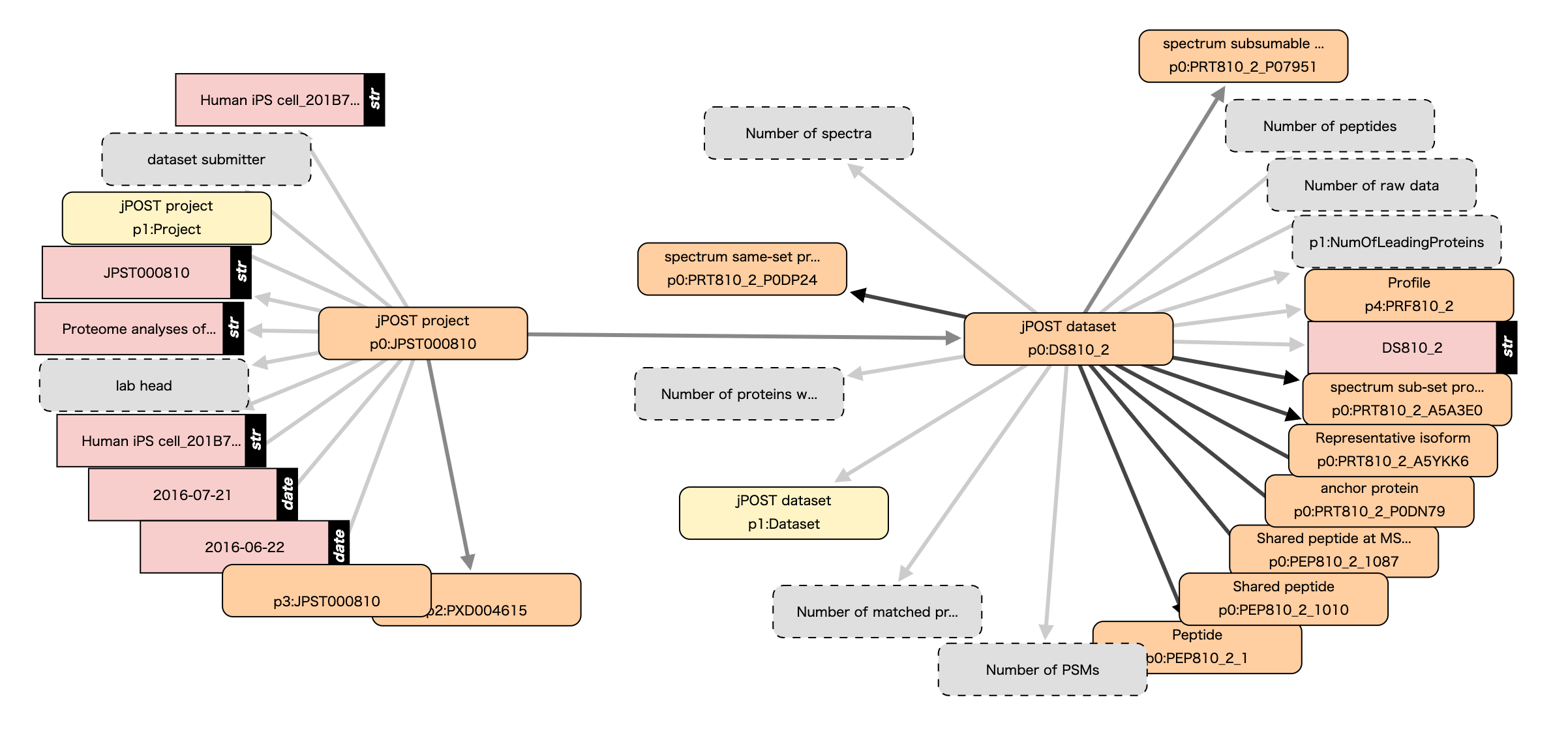
ここで全てを展開する必要はありませんが、RDF 構造が単純で見やすい場合は、ネットワークを視覚的に展開することも可能です
tips
RDF によっては初期のノードに全ての述語が繋がっていない場合もあります
その場合、初期ノードにコンマ区切りで複数の URI を入れることで、補完しあうことが可能です
また、a:http://.../AnyClass のように prefix "a:" を用いて初期ノードに入力することで、指定したクラスを持つ主語全体を初期ノードとすることが可能です(が、重くなると考えられるので SPARQL クエリが返ってくるかは場合によります)
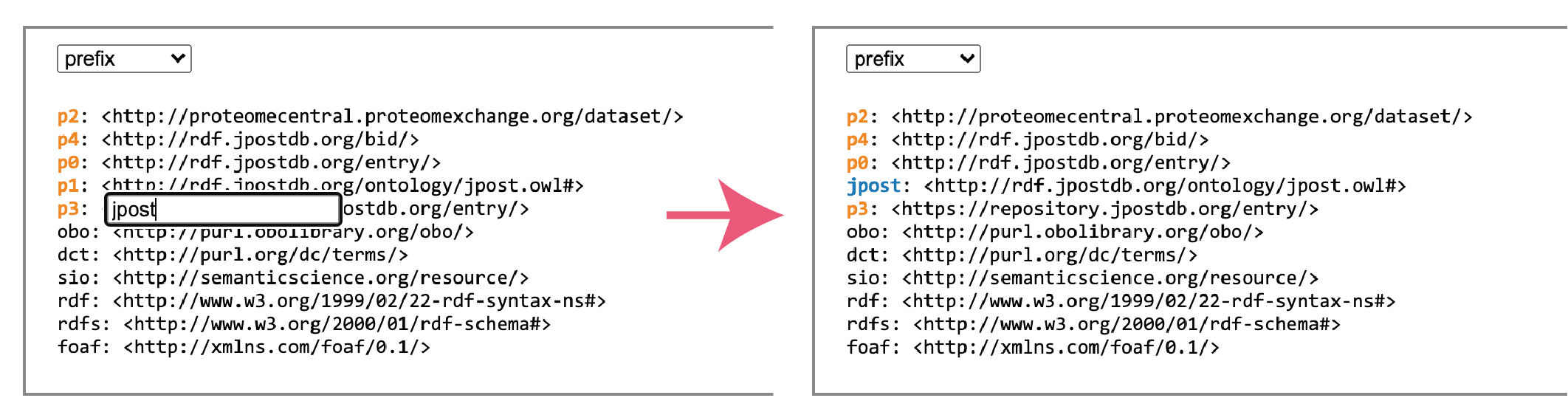
2) prefix を修正する
はじめてアクセスしたときは、定番のもの以外は prefix が自動でついた "p + 数字" などとなっているので変更します(変更しなくても、RDF-configやSPARQLの構文に問題はありません)
コントローラの "RDF-config" をクリックして ON にします

使用中の prefix のリストが表示されます
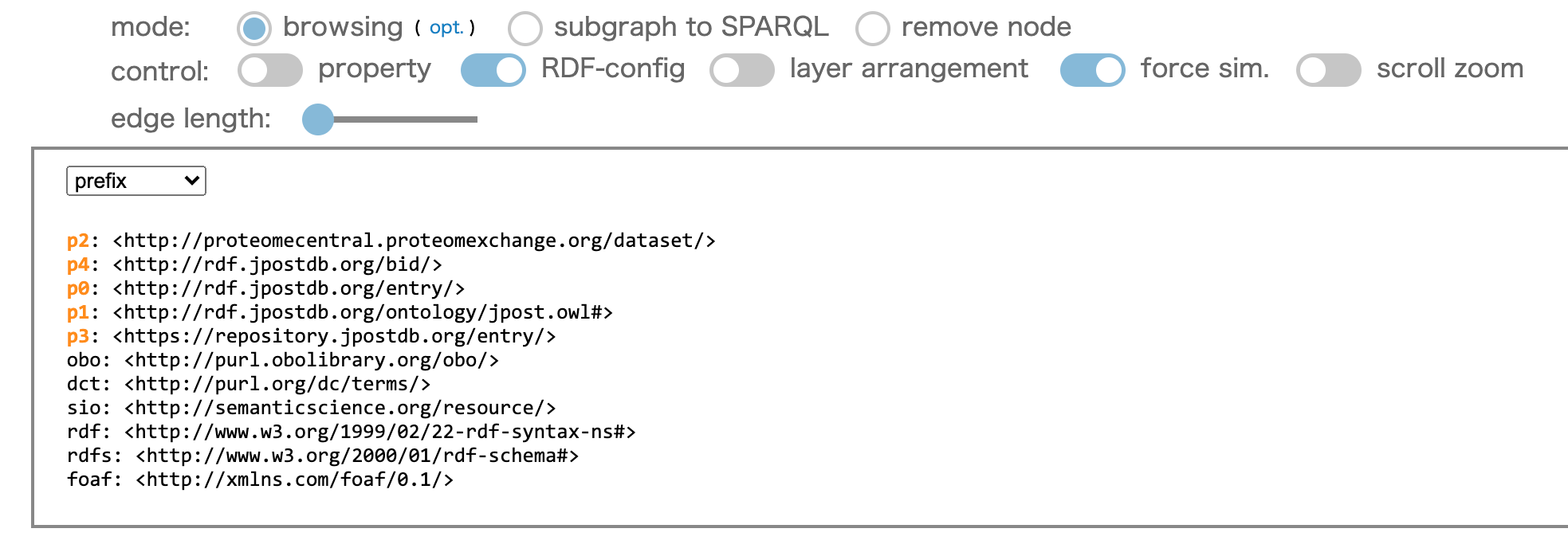
はじめから、青色で表示されている prefix は prefix.cc で取得したものです
オレンジ色の "p + 数字" で表示された prefix は自動で作成されたものです
クリックすると入力ボックスが出るので、好きな prefix に変更して enter キーで決定すると、青色になります(何度でも変更もできます)
フォーカスは Tab キーで変更でき、フォーカスされているときは Enter キーでも入力ボックスを出せます(もとの prefix のクリックか Esc キーで入力ボックスを閉じることが可能)
ブラウザのキャッシュに記憶されるので、次回からの変更は不要です
3) RDF-config の model 作成を開始する
プルダウンメニューから "model" を選択します
手順 1) でのネットワーク図での展開に応じて、未完成の RDF-config model が表示されます(この model からもネットワークを展開できるので、手順 1) で全てを展開している必要はありません)

手順 1) で最初に入力したノードを主語の例とした、シンプルな model が表示されています
構造の説明については RDF-config specification を参照下さい
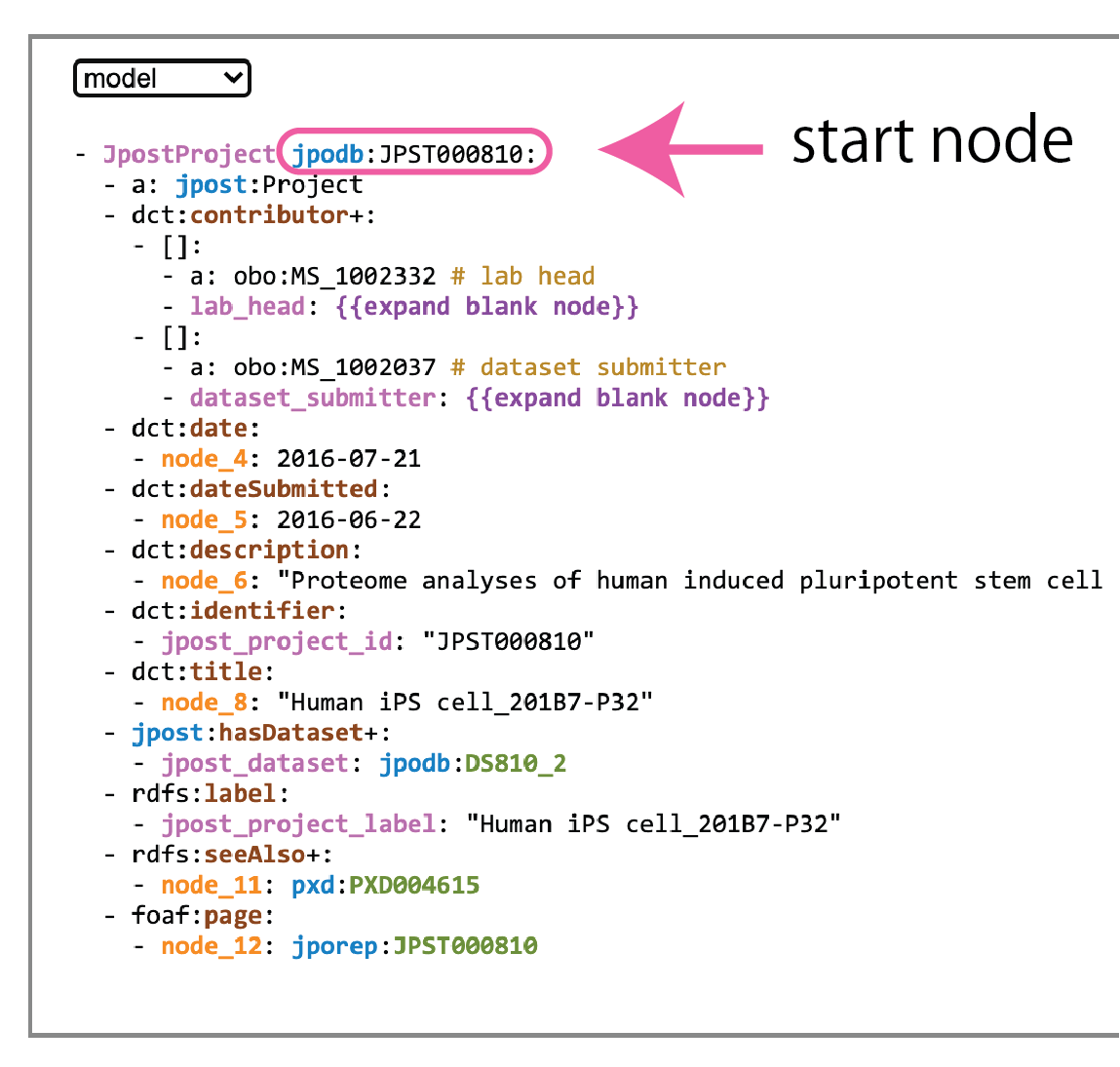
URI が通し番号っぽい ID になっている型や述語には、ラベルがコメントとして表示されています
その他の色のついた部分はクリッカブルになっており、model の編集に使用します
4) 主語と目的語の名前を編集する
主語や目的語の名前は、SPARQL 検索や結果を表示する際に利用する変数名となります
ピンク色の主語や目的語の名前は、type のラベルなどから自動的に生成したものになります。必要に応じて変更します。ラベルや述語依存なので、同じ変数名が割り当てられる場合があるので注意してください
prefix の時と同様にクリックか Enter キーで入力ボックスが開きます
適当な名前が割り当てられなかったオレンジ色の "node_ + 数字" の主語や目的語も変更します
RDF-config では、主語は CamelCase、目的語は snake_case で記述します(スペース区切りで入力すると自動で変換されます)
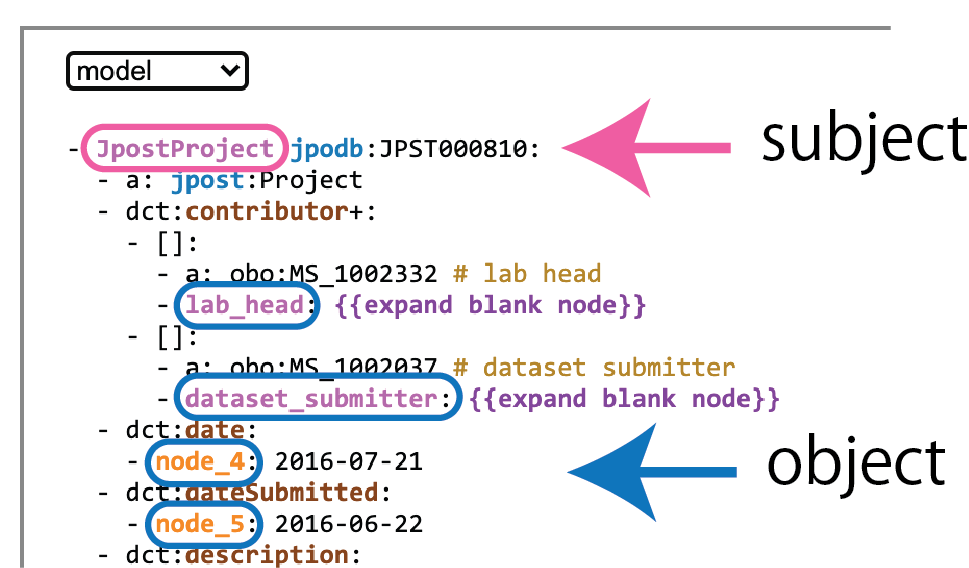
prefix の変更はここでもできます
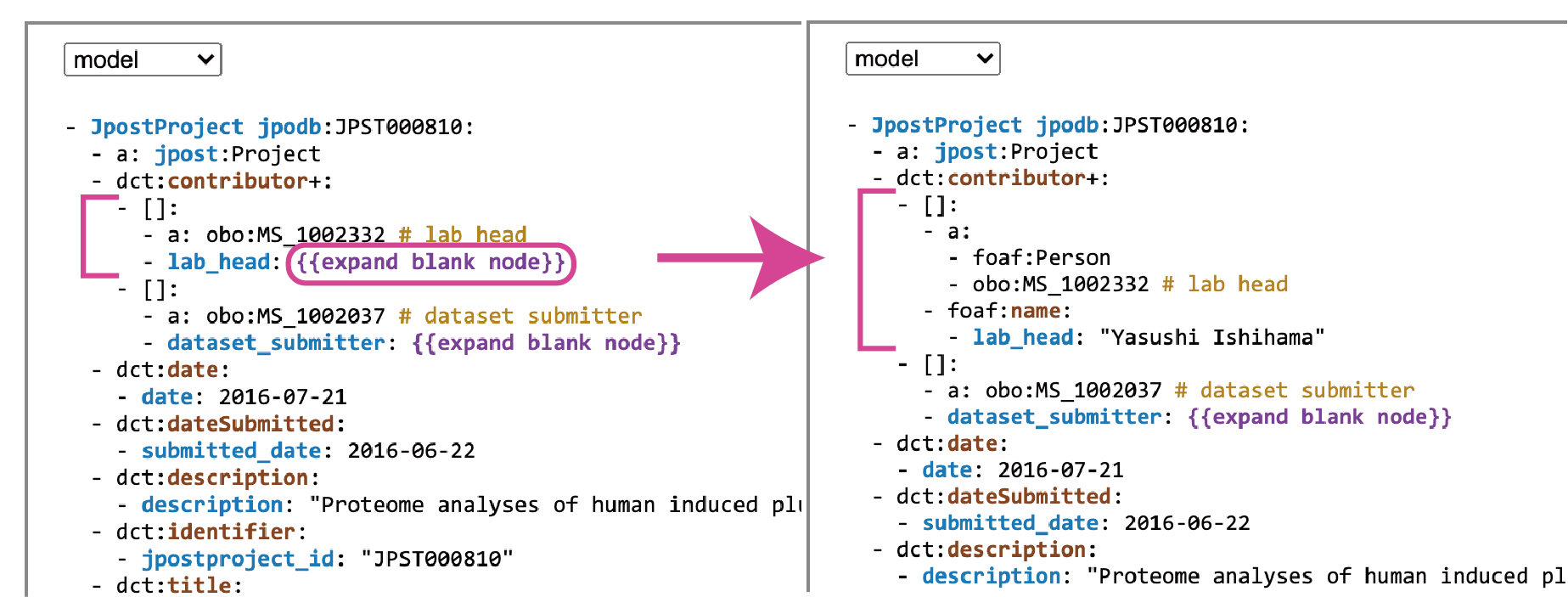
5) ブランクノードを展開する
手順 1) で展開していなかったブランクノードは {{expand blank node}} をクリックすることで展開できます
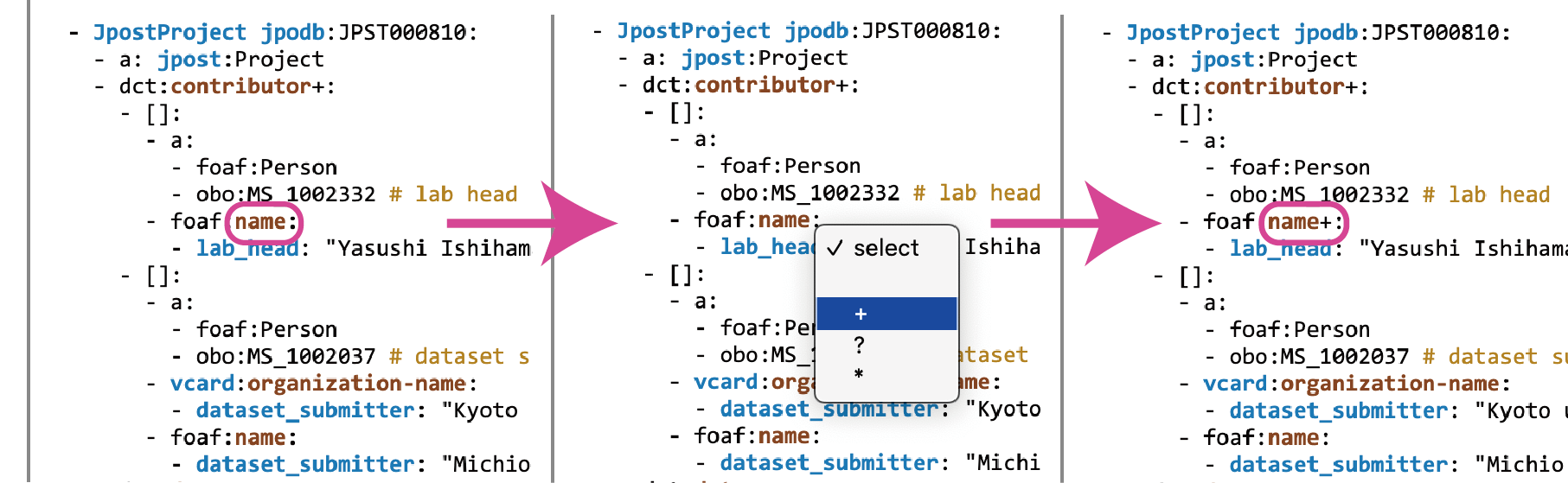
6) 目的語の出現回数の制約を指定する
RDF-config では述語に対応する目的語に許容される出現回数の制約を、述語の末尾に下記の記号をつけることで明示できます
茶色の述語をクリックすることでプルダウンメニューが出現するので、適したものを選択します
記号の意味の参照(個数指定の{n}, {n,m} については未対応)
クラス指定した主語(Limit 100 万)での述語の有無から、ある程度自動で推定してつけます(主語が 100 万以下なら正しいですが、それより多い場合は全探索ではないので、正しい保証はないです)
7) 目的語から新規に主語を定義して model を展開する
目的語をさらに展開して model を構築したい場合には、目的語を新たな主語として定義することができます
緑色の目的語の例をクリックすることで、プルダウンメニューが出現するので、"new subject" を選択することで、model の一番下に新たに主語として追記されます
"object" を選択すると、何も起こらずそのまま目的語として扱われます
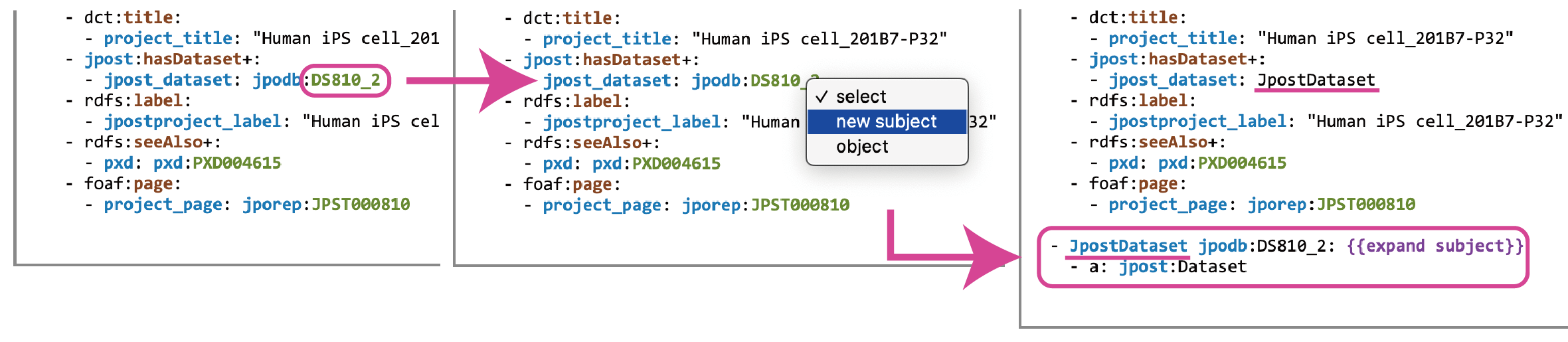
手順 1) で展開していなかった場合は {{expand subject}} をクリックすることで展開できます

新たな主語の model で手順 4) - 7) を繰り返すことで RDF-config を構築できます
{{ hoge hoge }} の形の記述が残っていると正しい RDF-config にはなりません
コントローラの "RDF-config" をクリックして OFF にすると、展開されたネットワーク図の惨状現状を眺めることもできます
8) model のチェック
プルダウンメニューの "--senbero" から、サーバーで RDF-config を走らせることで --senbero と --schema の出力をチェックできます
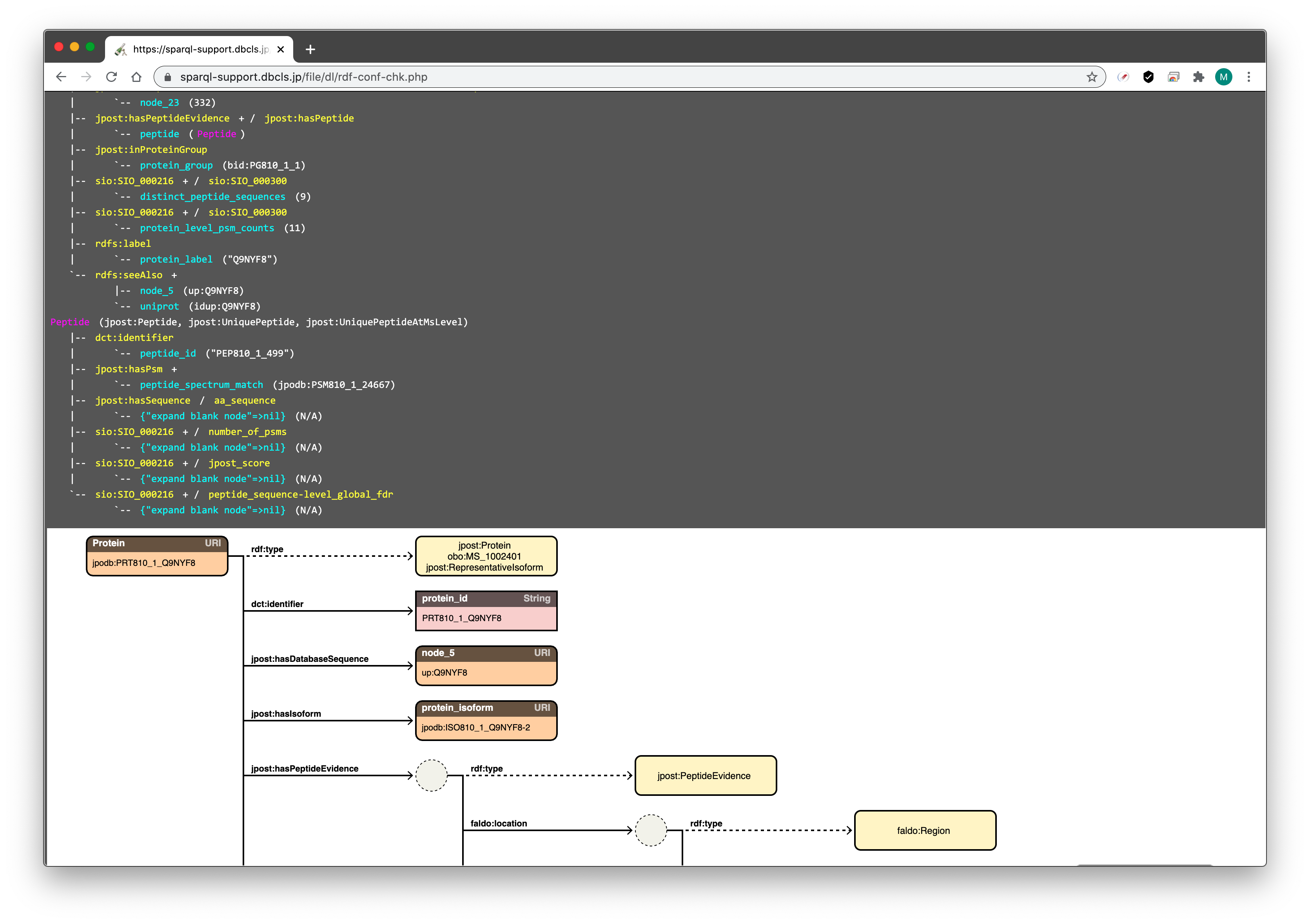
(注意:ポップアップウィンドウをブロックしているとチェックウィンドウが開きません)
(副産物の RDF-config checker。RDF-config インストール面倒な人用)
9) RDF-config のダウンロード
プルダウンメニューの "* download" から、RDF-config が tar 形式でダウンロードできます
endpoint, prefix, model, sparql, metadata の yamlが入っています(sparql は下記参照。metadata は例ですので書き換えが必要です。stanza.yaml は未対応)
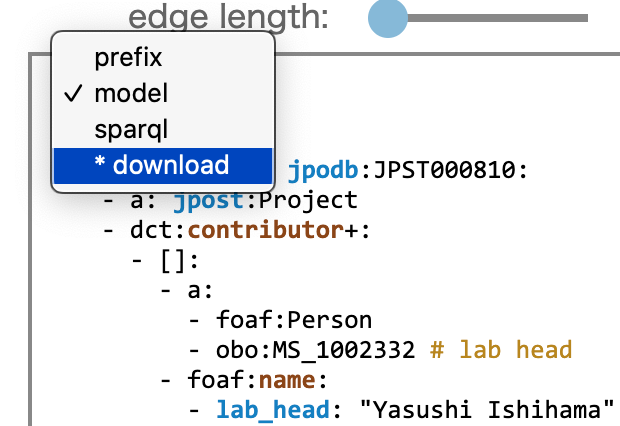
(注意:ポップアップウィンドウをブロックしているとダウンロードできない可能性があります)
yaml ファイルの入ったディレクトリを、RDF-config の --config オプションでを指定して用います。--senbero でエラーが出ないか確認して下さい
プルダウンメニューの "sparql" は、現状は、主語に置いた変数名を列挙しているだけ(主語のリストをSELECTで取得するSPARQLクエリ)なので、必要に応じてダウンロード後に変更してください
